What Can Uni-Mol Do too? | Predicting the molecular properties of battery electrolytes with the integrated KPI framework
With the growing market demand for efficient and safe rechargeable batteries that can operate under extreme temperature conditions, the rapid and accurate evaluation of key properties of electrolyte molecules has become particularly important. A recent paper titled "A Knowledge–Data Dual-Driven Framework for Predicting the Molecular Properties of Rechargeable Battery Electrolytes," published in Angewandte Chemie International Edition, details an innovative approach known as the "Knowledge–Data Dual-Driven Framework" (KPI) specifically designed to predict the molecular properties of battery electrolytes, including melting point (MP), boiling point (BP), and flash point (FP). The research team skillfully combined deep learning techniques with domain-specific chemical knowledge, supported by large-scale datasets, significantly enhancing the accuracy and efficiency of predictions. In this framework, the Uni-Mol model plays a central role, demonstrating great potential in predicting the properties of electrolyte molecules and providing strong support for the development of next-generation high-performance batteries.
Xiang Chen, an associate research fellow in the Department of Chemical Engineering at Tsinghua University, is the corresponding author of the paper. Yuchen Gao, a 2022 direct-entry PhD student in the Department of Chemical Engineering, is the first author. Co-authors include Yuhang Yuan, an undergraduate from the Tsinghua Academy of Wisdom; Suozhi Huang, an undergraduate from the Institute for Interdisciplinary Information Sciences; Nan Yao, a 2020 direct-entry PhD student; Legeng Yu, a 2021 direct-entry PhD student; Yaopeng Chen, a 2023 direct-entry PhD student; and Qiang Zhang, a professor in the Department of Chemical Engineering. The research was supported by funding from the National Natural Science Foundation of China, the National Key R&D Program of China, and the Beijing Natural Science Foundation.
1. Research Background
Secondary batteries have been widely used in electric vehicles and portable electronic devices. However, with the diversification of application scenarios—such as extreme cold, desert regions, and specialized settings like aerospace, underground exploration, and medical device sterilization—the demand for batteries to maintain stable performance under extreme temperatures has become increasingly urgent.
In high-temperature environments, side reactions between electrolytes and active materials intensify, not only consuming electrolytes and active substances but also potentially triggering thermal runaway, posing serious safety risks. Conversely, in low-temperature conditions, the kinetics of electrochemical reactions are significantly reduced, which can lead to the formation of lithium dendrites, further increasing safety hazards. Therefore, developing batteries capable of safe operation across a wide temperature range has become a critical technical challenge.
Moreover, battery performance heavily depends on the physicochemical properties of electrolytes, such as melting point, boiling point, and flash point. Traditional experimental methods, however, are inefficient due to limited data and reliance on trial-and-error processes, making them inadequate for the rapid development of new electrolyte molecules. Against this backdrop, efficient molecular property prediction models and high-throughput screening tools are particularly important to support the advancement of battery research toward higher performance and enhanced safety.
2. Methods
In this paper, the research team developed an innovative approach called the Knowledge–Data Dual-Driven Framework (KPI) for predicting the molecular properties of secondary battery electrolytes. The KPI framework consists of three main modules: data organization and statistical analysis, interpretability and knowledge discovery, and knowledge-based molecular property prediction. First, the KPI framework collects molecular structure and property data from public databases and literature and automatically organizes it into structured datasets. Next, it employs interpretable machine learning methods to explore structure–property relationships from a microscopic perspective. Finally, the discovered knowledge is embedded into property prediction models.
Uni-Mol, serving as a foundational model, is utilized for molecular property prediction within the framework. It integrates a knowledge embedding mechanism to enhance prediction performance through pretraining and fine-tuning.
Pretraining:
Uni-Mol undergoes pretraining on a large dataset of chemical molecules (in SMILES notation) to learn the underlying relationships between molecular structures and properties. This process provides a robust molecular representation foundation for property prediction.Knowledge Embedding and Fine-Tuning:
For specific tasks (e.g., predicting melting point, boiling point, and flash point), Uni-Mol integrates critical information extracted from data and chemical knowledge through a knowledge embedding mechanism. This mechanism uses a knowledge purity controller and a knowledge flow controller to adjust the proportion and dimensionality of embedded knowledge vectors, significantly improving the model's prediction accuracy.Efficient Screening and Molecular Design (KPI-Assisted Electrolyte Molecular Design):
The fine-tuned Uni-Mol achieves high accuracy in predicting molecular properties, enabling high-throughput screening to quickly identify molecules with excellent performance. This supports the development of wide-temperature-range and high-safety electrolytes.
3. Results and Discussion
3.1 Overview of the KPI Framework Architecture
Figure 1 provides a detailed illustration of the three core modules of the Knowledge–Data Dual-Driven Framework (KPI) and their collaborative operational process. First, the data organization and statistical analysis module collects molecular structure data along with properties such as melting point, boiling point, and flash point from public databases and literature. Through data cleaning and statistical analysis, the information is organized into structured tables. Clustering analysis and chemical space visualization techniques are then used for preliminary screening of potential molecules, laying the groundwork for subsequent research. Next, the interpretability and knowledge discovery module extracts molecular descriptors (e.g., the number of atoms, bond types, functional groups) and employs the Shapley Additive Explanations (SHAP) algorithm to reveal microscopic relationships between molecular structures and properties. The generated chemical knowledge serves as prior information for downstream models, enhancing the scientific interpretability and accuracy of predictions. In the knowledge-based molecular property prediction module, Uni-Mol is employed for molecular property prediction. Its pretrained model provides robust molecular representation capabilities, capturing complex structural features. By integrating chemical knowledge during fine-tuning, Uni-Mol embeds knowledge vectors at molecular, bond, and atomic levels. These vectors are dynamically optimized by the knowledge purity and knowledge flow controllers, achieving high-precision predictions for target properties such as melting point, boiling point, and flash point.
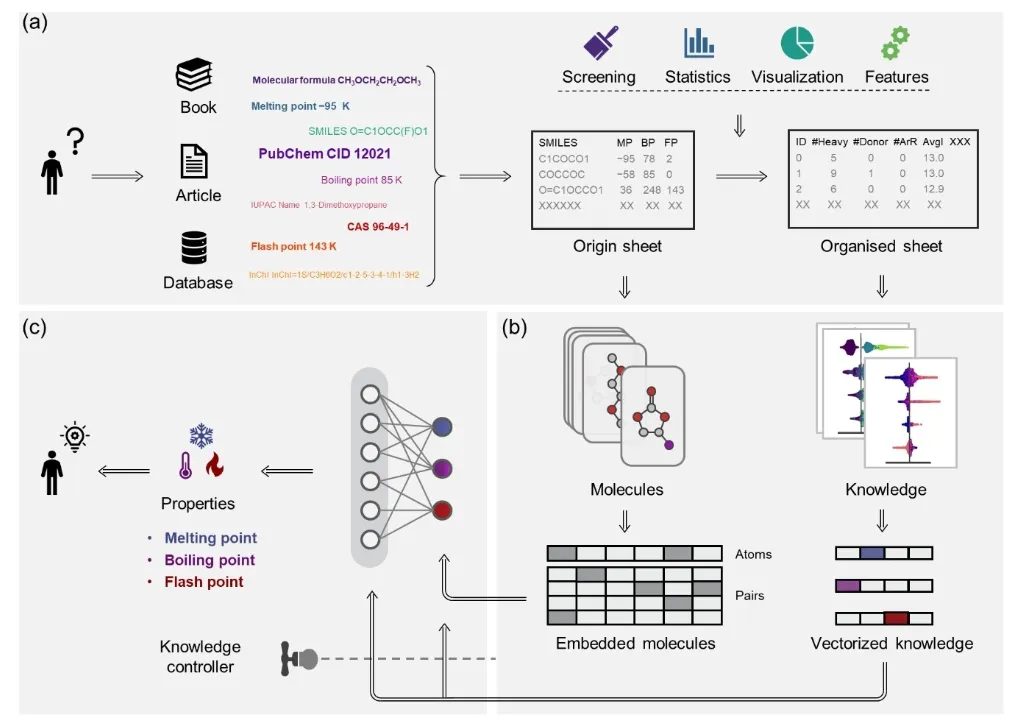
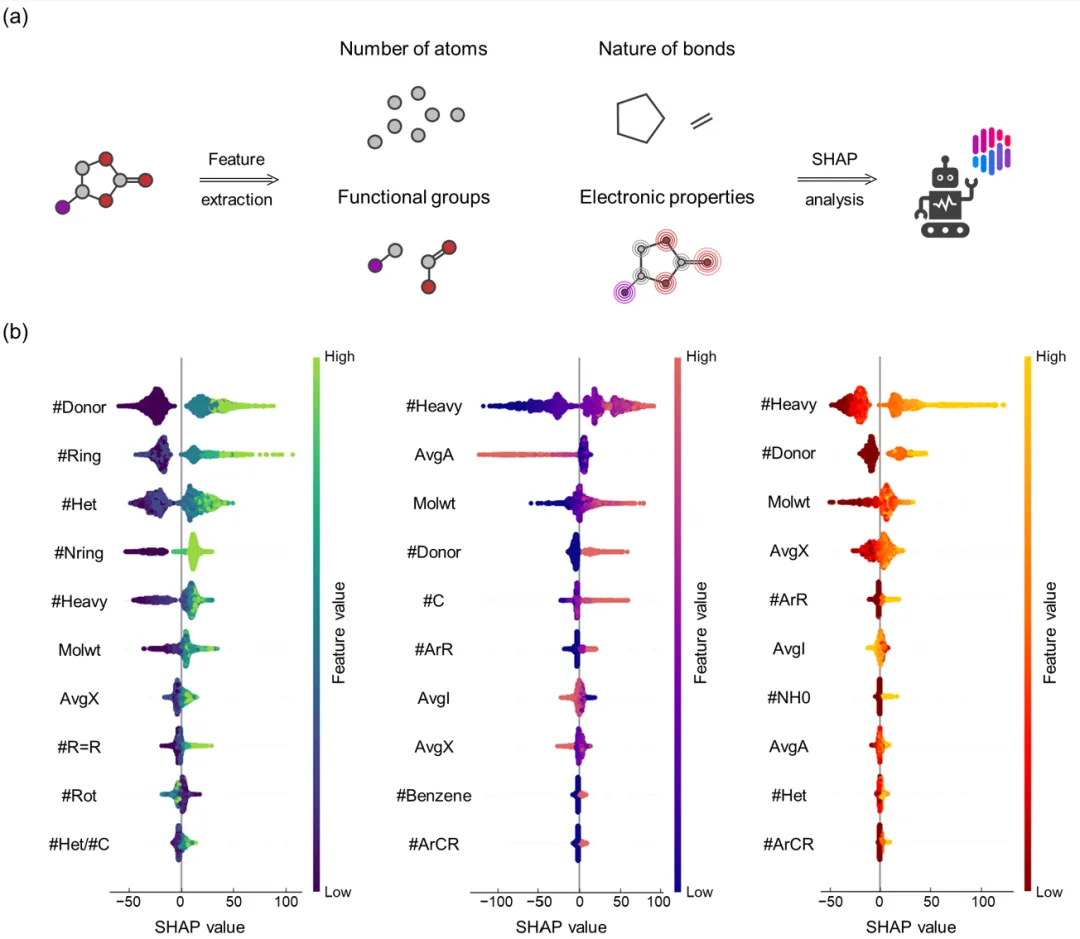
3.2 Data Analysis and SHAP Visualization in the KPI Framework
Figure 2 uses the SHAP algorithm to analyze the contributions of molecular features to melting point, boiling point, and flash point, identifying the key factors influencing model decisions. The study extracted 64 molecular descriptors (e.g., number of atoms, bond properties, functional groups) and focused on the top ten important features for each property.
For melting point, the key influencing factors include the number of hydrogen bond donors (#Donor), the number of rings (#Ring), and the number of double bonds (#R=R). Among these, hydrogen bond donors significantly increase melting points by enhancing intermolecular attractions. For boiling point and flash point, major features include the number of heavy atoms (#Heavy) and molecular weight (Molwt), reflecting the higher thermal stability of larger molecules. Additionally, electronic properties such as average electronegativity (AvgX) also moderately influence boiling point and flash point. These analyses uncover the deep correlations between molecular structures and properties, providing valuable references for model prediction and molecular design.
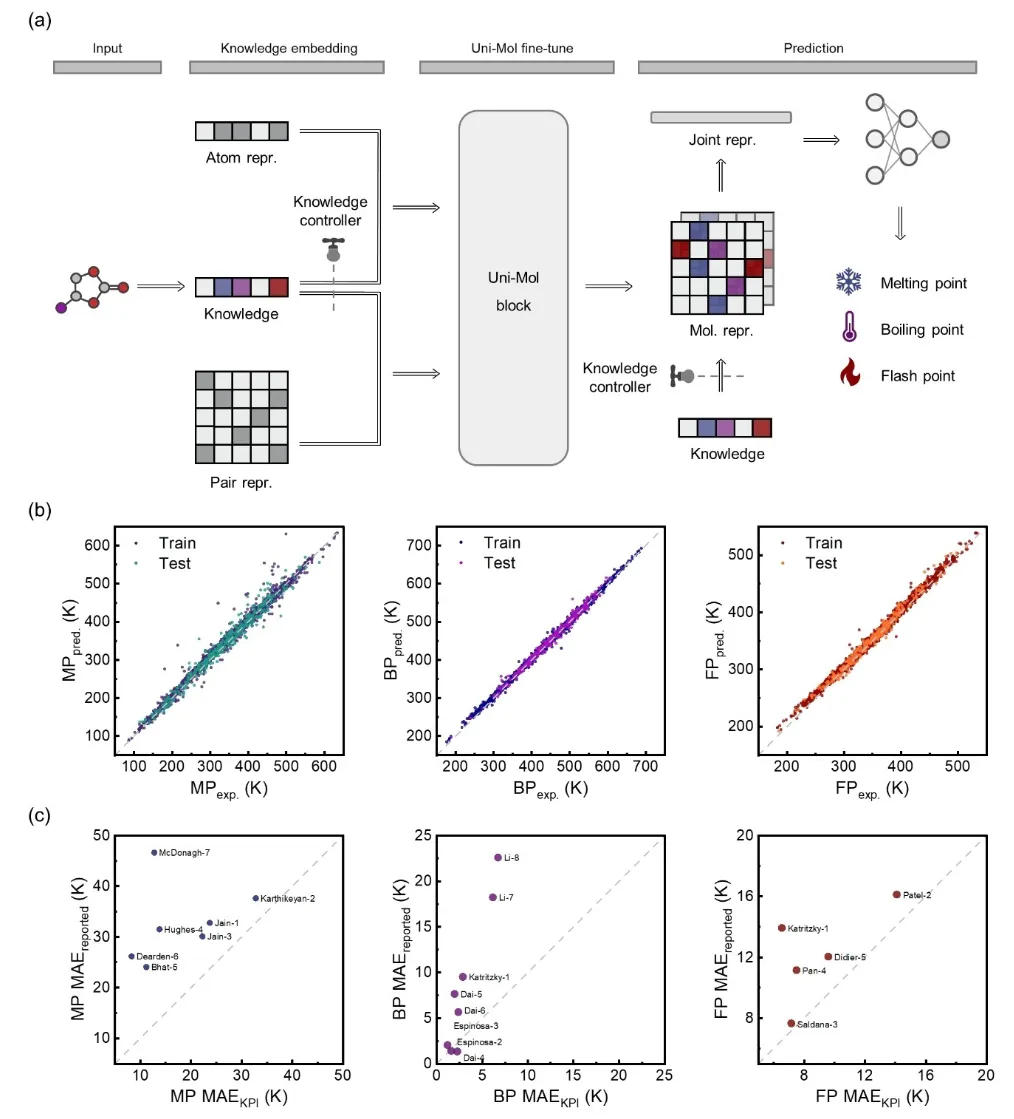
3.3 Knowledge-Based Learning Models and Performance Evaluation
1. Knowledge-Embedded Model Architecture
The model takes molecular conformations as input, encodes information about atoms and bonds, and uses Uni-Mol as the foundational model for molecular structure representation. Uni-Mol’s base molecular representation is adjusted using the knowledge purity and knowledge flow controllers, embedding multi-level chemical knowledge (including molecular, bond, and atomic levels) to enhance prediction performance. The knowledge-enhanced molecular representation is further optimized using a Transformer encoder to accurately predict target molecular properties such as melting point, boiling point, and flash point.
2. Prediction Results and Accuracy
The figures display the prediction results for melting point, boiling point, and flash point, with training and test sets distinguished by color. Data points closer to the diagonal line indicate higher prediction accuracy. The integration of Uni-Mol’s robust molecular representation capabilities with embedded knowledge significantly improves prediction precision.
3. Model Comparisons
Tests across various datasets demonstrate that the KPI framework achieves state-of-the-art (SOTA) performance on 18 benchmark datasets. Compared to the Uni-Mol model without knowledge embedding or traditional methods (e.g., Random Forest), the knowledge-embedded Uni-Mol significantly reduces prediction errors (MAE).
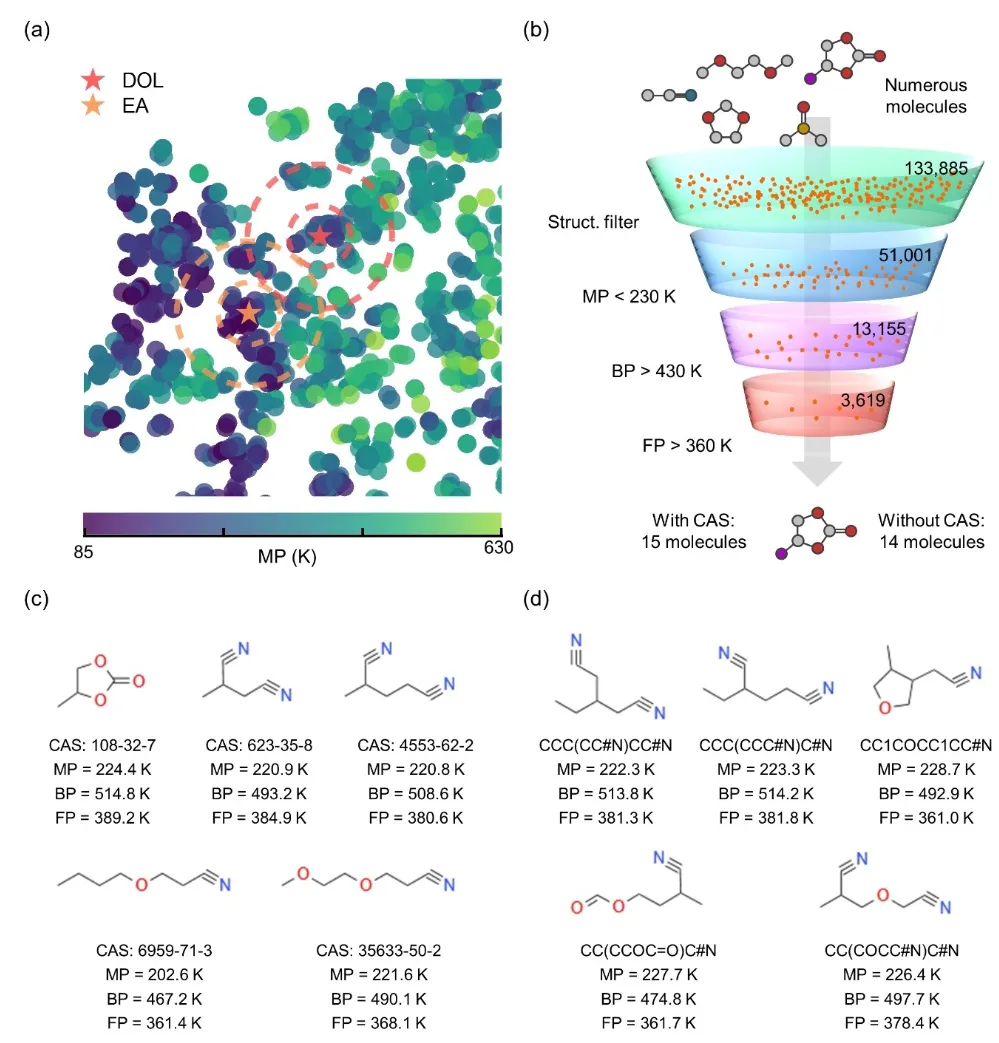
3.4 Facilitating Advanced Molecular Screening and Design with the KPI Framework
Figure 4 showcases the specific applications of the KPI framework in molecular proximity search, high-throughput screening, and the presentation of screening results. In molecular proximity search, performance-optimized molecules (e.g., 1,3-dioxolane, DOL) serve as centers for first- and second-degree searches, identifying candidate molecules with similar properties, such as tetrahydrofuran (THF).
For high-throughput screening, the KPI framework processes extensive databases (e.g., QM9 with 133,885 molecules) to identify molecules meeting criteria such as a melting point below 230 K, a boiling point above 430 K, and a flash point above 360 K. Multi-level filtering significantly narrows the search scope, ultimately pinpointing molecules with potential for wide-temperature-range and high-safety applications.
In the presentation of screening results, Figure 4c lists 15 registered molecules (with CAS IDs), including their molecular structures, SMILES notations, and properties such as melting point, boiling point, and flash point. Figure 4d highlights 14 unregistered molecules (without CAS IDs), further demonstrating the KPI framework’s powerful capabilities in discovering novel molecules.
Conclusions
This study proposes a dual-driven framework combining knowledge and data (KPI), offering a novel approach to the development of wide-temperature-range, high-safety electrolytes by accurately predicting the melting point, boiling point, and flash point of electrolyte molecules. The KPI framework not only achieves breakthroughs in predictive performance but also successfully identifies various potential molecules with outstanding properties through high-throughput screening and proximity searches.
By leveraging the pretrained Uni-Mol model integrated with knowledge embedding techniques, the KPI framework significantly enhances the accuracy of molecular property predictions while providing a deeper understanding of the relationships between molecular structure and properties. The results demonstrate that this framework can greatly accelerate the design and discovery of novel electrolyte molecules, providing theoretical guidance and technical support for the development of next-generation batteries.
In the future, the KPI framework is expected to find broad applications in other fields of molecular design, such as drug discovery and catalyst design, offering more efficient tools and methods to drive scientific innovation.