DeePMD-kit v3 Tutorial 2 | DPA-2 Model, Multi-Task Training, and Fine-Tuning
The second highlight of DeePMD-kit v3 is the DPA model and training strategies such as multi-task training and fine-tuning. This article introduces these features from two aspects: background and principles and usage tutorials.
Background and Basics
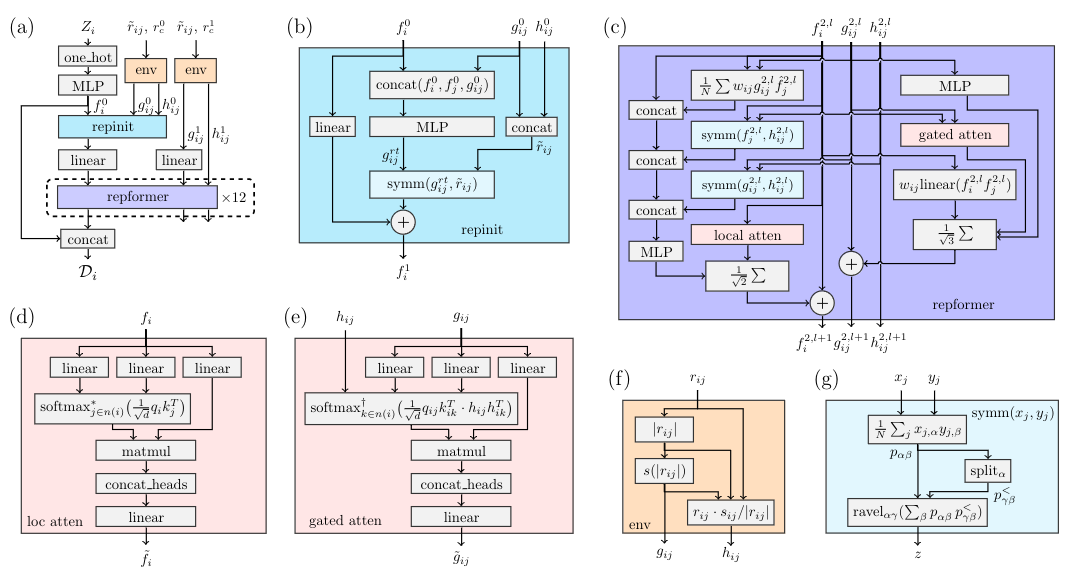
The DPA-2 model consists of two main modules: repinit and repformer.
- Repinit: Initializes the descriptors.
- Repformer: Iteratively refines the descriptors through multiple iterations (denoted as
x12in the diagram).
In the input file, these two components are also separated into two distinct sections for configuration.
1 | "descriptor": { |
Under normal circumstances, repinit initializes the descriptors using the two-body DeepPot-SE. When use_three_body is set to true, three-body descriptors are also included.
For repformer, the parameters g1 and g2 represent:
- g1: Single-body descriptors
- g2: Two-body descriptors
The DPA-2 model includes three places where rcut (cutoff radius) and nsel (neighbor selection) need to be configured. It is crucial to ensure these values are set correctly to avoid inconsistencies or errors during training and inference.
Tutorial
This tutorial can be run directly in a Notebook on Bohrium:
https://bohrium.dp.tech/notebooks/51511526135/
Single-Task Training from Scratch
Clone the DeePMD-kit repository and navigate to the DPA-2 example directory:
1
2git clone https://github.com/deepmodeling/deepmd-kit
cd deepmd-kit/examples/water/dpa2The
dpa2folder contains three JSON files for training configuration:input_torch_small.json,input_torch_medium.json, andinput_torch_large.json. These differ in model size and training speed:- Small:
update_g2_has_attnis set tofalse. - Medium:
update_g2_has_attnis set totruewith 6 layers (nlayers). - Large:
update_g2_has_attnis set totruewith 12 layers (nlayers).
- Small:
Use the medium configuration as an example:
- Set the training steps to 10,000:
1
sed -i "s/1000000/10000/g" input_torch_medium.json
- Train the model:
1
dp --pt train input_torch_medium.json
- Freeze the trained model:
1
dp --pt freeze
- Set the training steps to 10,000:
This generates a PyTorch model (
frozen_model.pth). Convert it to a JAX-compatible format (frozen_model.savedmodel):1
dp convert-backend frozen_model.pb frozen_model.pth
Performance Test:
On an H100 GPU, the dynamics simulation speed for 500 steps (12,000 atoms) is:1
2PyTorch: 321.824 steps/s
JAX: 324.792 steps/s
Multi-Task Training from Scratch
- Switch to the multi-task example directory:
1
2mkdir -p ../multi_task
cd ../multi_task - Download the multi-task training configuration:
1 | wget https://github.com/deepmodeling/deepmd-kit/raw/f1ecf95475a9aeef1abcb480f5d3bd0765d3b403/examples/water_multi_task/pytorch_example/input_torch.json |
- Set the training steps to 1,000:
1
sed -i "s/100000/1000/g" input_torch.json
- Train the multi-task model:
1
dp --pt train input_torch.json
Key Notes on Multi-Task Configuration:
- The
input_torch.jsondefines two tasks:water_1andwater_2. - The configuration uses:
shared_dict(e.g.,type_mapanddescriptor) for shared parameters across tasks.model_dict,data_dict, andloss_dictfor task-specific configurations.
- Freeze the model for individual tasks:
- For
water_1:1
dp --pt freeze --head water_1 -o water_1.pth
- For
water_2:1
dp --pt freeze --head water_2 -o water_2.pth
- For
Single-Task Training with a Pretrained Model
Create a new directory for fine-tuning:
1
2mkdir -p ../../water/finetune
cd ../../water/finetuneDownload the pretrained model and configuration file:
1
2wget https://store.aissquare.com/models/41d1cfb7-1a98-42a2-90a8-e6257db431ea/DPA2_medium_28_10M_rc0.pt -O finetune.pt
wget https://store.aissquare.com/models/41d1cfb7-1a98-42a2-90a8-e6257db431ea/input_torch_medium.json -O input_torch_medium.jsonSet the training steps to 1,000:
1
sed -i "s/10000/1000/g" input_torch_medium.json
Train using the pretrained model:
1
dp --pt train input_torch_medium.json --finetune finetune.pt --model-branch H2O_H2O-PD
Freeze the fine-tuned model:
1
dp --pt freeze
Testing Models:
Compare the models trained from scratch and fine-tuned models:- From scratch:
1
dp --pt test -m frozen_model.pth -s ../data
- Pretrained:
1
dp --pt test -m ../dpa2/frozen_model.pth -s ../data
- From scratch:
Results:
| Model | E RMSE | F RMSE |
|---|---|---|
| Scratch | 5.290549e-01 | 6.017190e-02 |
| Pretrained | 5.755728e-02 | 2.978876e-02 |
The fine-tuned model achieves significantly higher accuracy despite the demonstration's limited training steps.
Multi-Task Training with a Pretrained Model
For instructions on multi-task fine-tuning with pretrained models, refer to the official documentation.